

最長共通部分列(Longest Common Sequence, LCS)は、2つの文字列X, Yに共通して含まれる最長の部分文字列のことで、XとYの類似度を表す一つの尺度として用いられます。
本記事では、最長共通部分列の効率的な求め方を初心者向けに丁寧に解説し、最長共通部分列を用いたユニークな(役立つかもしれない)検索方法を紹介します。
最長共通部分列をすでに知っている方は、3章から読んでください。
なお、本記事のコードは、GithubのJupyter Notebookにもまとめてありますのでご覧ください。
最長共通部分列(Longest Common Sequence, 以下、本文中LCS)は、2つの文字列X, Yが共有する最長の部分文字列です。このとき、部分文字列はX, Yそれぞれの中で必ずしも連続していなくて良いです。
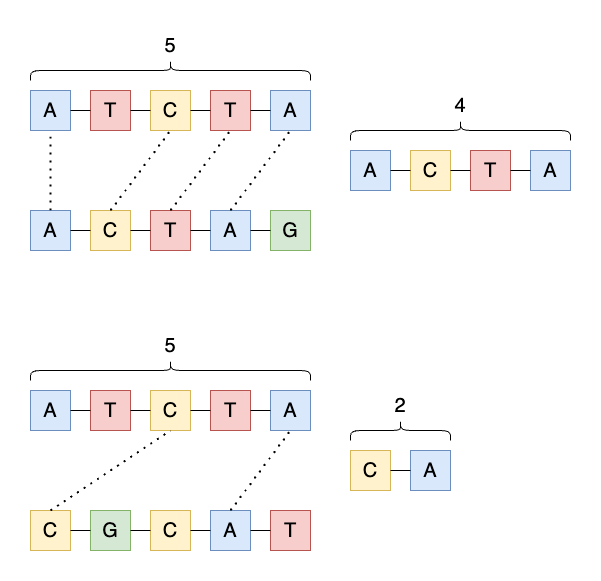
例えば、文字列abcdefgと文字列axxbxxxcの最長共通部分列はabcで、その長さは3となります。
異なる生物のDNAの類似度(距離)を測定する1つの尺度として、LCSを利用する場合があります。
DNAの配列は、A, T, G, Cの4文字からなりますが、DNA全体の長さに対するLCSの長さが大きければ、2つの生物のDNAの類似度は高い(可能性が)あります。
仮に、LCSを愚直に求めようとした場合、Xの部分文字列とYの部分文字列(しかも、連続しているとは限らない)を列挙する必要があり、Xの長さがN、Yの長さがMとすると、2M x 2N通りを調べなければなりません。
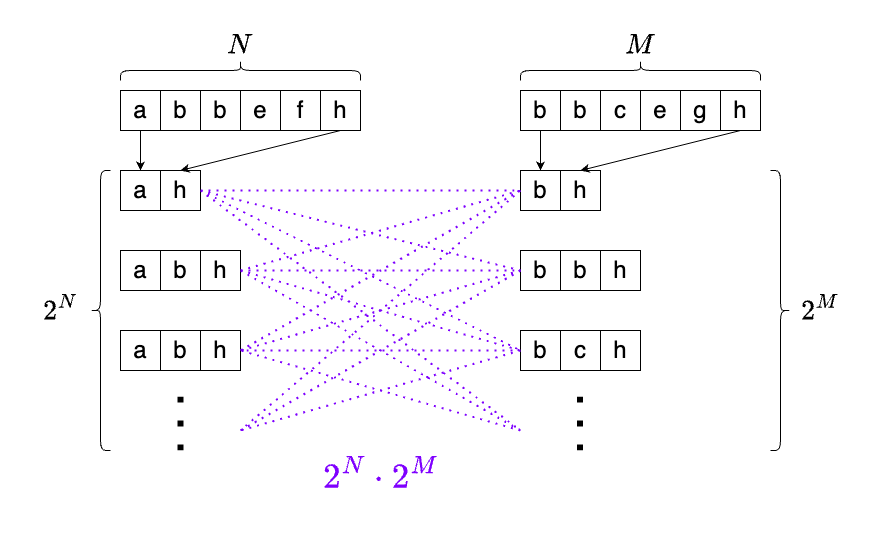
このままでは、とても現実的な時間内に求められません。
アルゴリズム的な改善により、LCSをO(NM)で求められることがわかっています。次章ではその方法を解説します。
LCSを考えるコツは「1文字ずつ進めて考える」です。X=ABCとY=ABDを考えます。
XとYのLCSは明らかにABで、その長さは2です。
しかし、一般の文字列に対してLCSを求めるアルゴリズムを考えるため、あえてXとYの1文字目から始めて、1文字ずつ進めて考えます。
以下、文字列Sのi文字目をS[i]、文字列Sの最初からi文字までを切り取った文字列をS[:i]と表記します。
X[:1]とY[:1]はAとAで、LCSはAで長さ1- 1文字ずつ進めて、
X[:2]=ABとY[:2]=ABを考える。B=Bだから、LCSはABになり、長さは1増えて2になる - 1文字ずつ進めて、
X[:3]=ABCとY[:3]=ABDを考える。C≠Dだから、LCSはABのままで、長さは2のままである - 以上より、XとYのLCSはABで、長さは2
このように、前の結果を使って次の結果を求めることができます。そして、それぞれのステップでは、XとYのi文字目が等しいかどうかのみに着目すれば良いことが分かります。
前の結果を使って次の結果を求めるアルゴリズムを、一般に動的計画法(Dynamic Programming, DP)と言い、LCS以外にも広範な応用例があります。
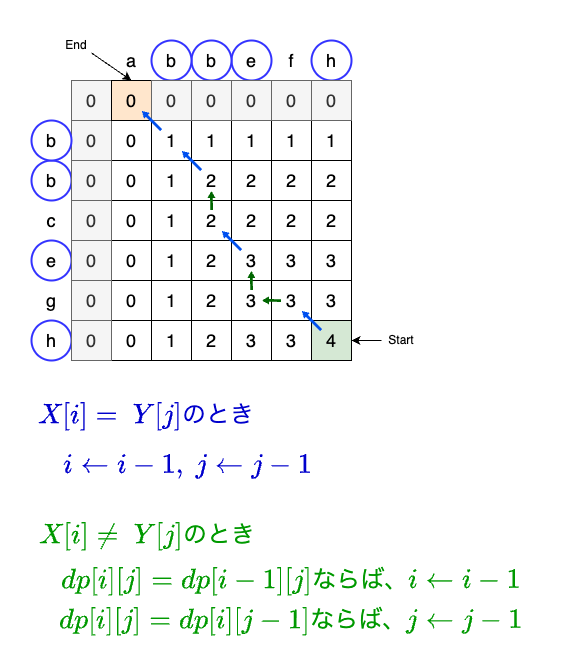
話を戻して、先ほどの話を一般の文字列に拡張します。図3に、文字列X = abbefhとY = bbceghのLCSを求める途中を書きました。
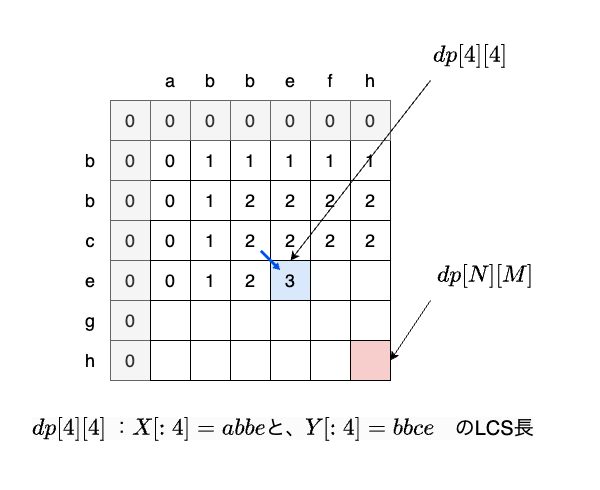
Xの長さがN、Yの長さがMの時、サイズ(N+1) x (M+1)のテーブルを用意し、テーブルを埋めるように求めていきます。
図3のようなテーブルは、LCSに限らず動的計画法全般で使用されるため、DPテーブルと呼ばれます。X[:i]とY[:j]のLCSの長さをdp[i][j]とすると、dp[N][M]が求めたい答えです。
dp[i+1][j+1]を前の結果を使って求める式は、以下の図4のようになります。
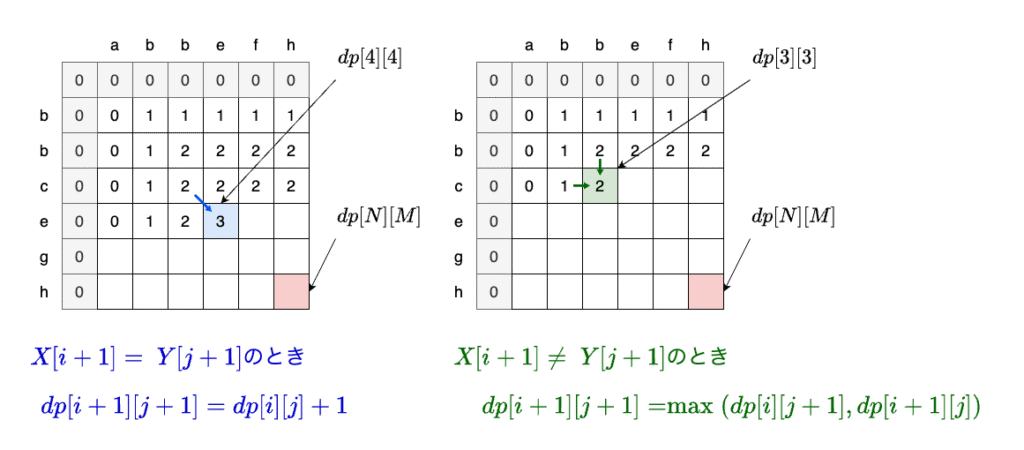
Xのi+1文字目とYのj+1文字目が異なる場合には、dp[i+1][j]とdp[i][j+1]の両方を見て、大きい方を取ります。Xのi+1文字目(またはYのj+1文字目)を加えた瞬間に、LCSの取り方が変化する場合があるからです。
これをdp[N][M]が埋まるまで繰り返します。計算回数は、dpテーブルのサイズと同じになるので、N x Mです。2M x 2Nと比べると、劇的な改善ですね。
以上で、LCSの長さを求めることができました。
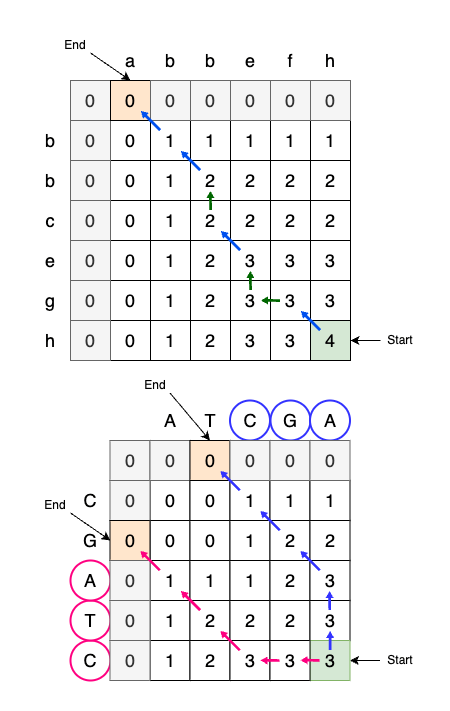
LCSそのものを復元するには、完成したDPテーブルをdp[N][M]から逆順にたどります。
LCSに1文字追加するたび、DPテーブル上では「X[i] = Y[j]なので、i -> i+1, j -> j+1と右下に移動」したはずなので、この移動を探しながら、図6のように探索します。
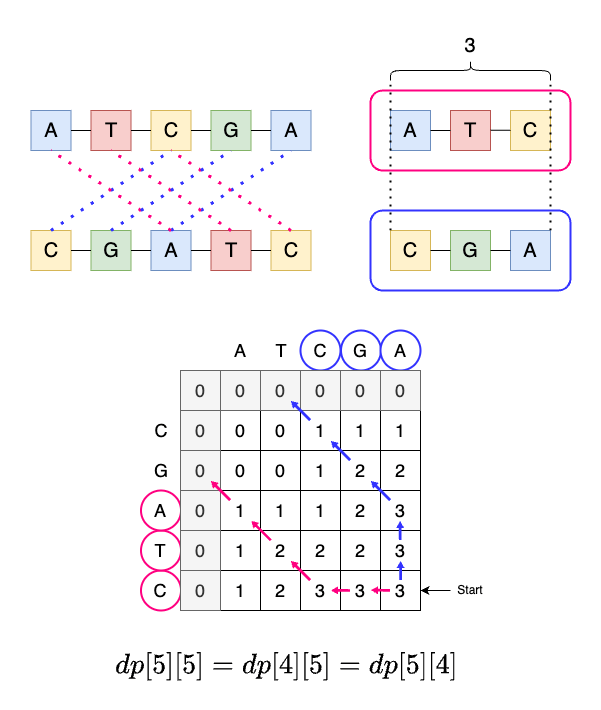
X, Yによっては、dp[i][j] = dp[i-1][j] = dp[i][j-1]となる場合がありますが、どちらに遷移しても構いません。
LCSが複数ある場合には、この分岐によって復元されるLCSが変わる可能性があります。例えば、図7のようなX, Yでは、ルートによって復元されるLCSが異なります。
仮に、複数のLCSのうち復元したいものに条件がある場合、i -> i-1とj -> j-1の遷移に優先順位を設けるなどの工夫をする必要があります。
以上から、LCSの長さとLCS自体の復元を行うコードは、Pythonで以下のように実装できます。
lcs_dp()は、文字列X, Yを与えると、(LCSの長さ, DPテーブル)のタプルを返す関数です。
lcs_from_tableは、X, Yと完成したDPテーブルから、LCSのうち1つを返す関数です。
LCS復元時の探索の終了条件が、N > 0かつM > 0であることに注意してください。
DPテーブル上での探索の終了位置はX, Yと探索経路によって異なるからです。
次章では、LCSを使用したユニークな検索方法を紹介します。
LCSを利用して、データを検索するユニークな方法を紹介します。ちなみに、ここで紹介する方法は、筆者が前に実務で使用したミニテクニックになります。
文字列X, YのうちXを固定して、多数のデータから条件つきでYを得ることを考えます。
例えば、LCSの長さがXの長さと同じになるようなYに絞り込んでみます。
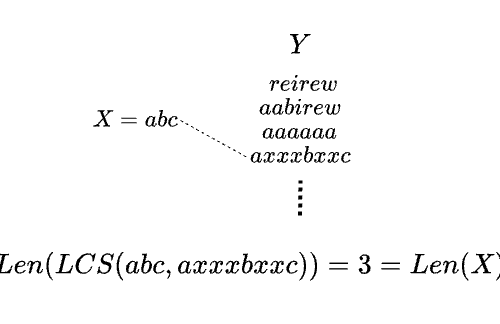
すると、検索されたYは、キーワードXを含む文字列になっています。
LCSがユニークなのは、「X, Yが共有する部分列は、X, Yの中では飛び飛びになっていても良い」という点でした。これを応用してみましょう。
次のようなファイル群を考えます。

資料名、日付、作成日をこの順に付与するルールはあるようですが、フルネームが入っていたり、記号が_のものがあったり、作成者ごとに微妙なずれがあります。
図10の中から、2025年2月分の営業日報を検索したいとき、Xを「営業日報202502」に固定し、LCSの長さがXの長さ=10になるものだけをYとすれば、一度の検索で完璧に絞り込み可能です。
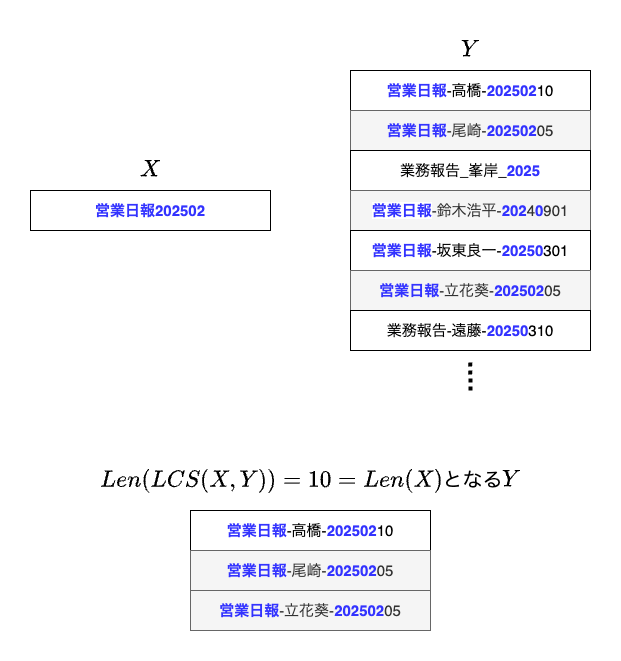
Pythonで実装すると、以下のようになります。ファイル名をLCSの長さで分類し、LCS長が10のものだけを出力しています。
うまく検索できました。指定するキーワードXを変更したり、絞り込み条件に使うLCSの長さを変更したりすると、様々な検索ができます。
昨今では、ほとんどの会社では文書もデータベースで管理されるようになりました。しかし、文書に様々な属性を付与して構造化しても、このようなズレへの対処や、特殊な検索が完全に不要にはならない場合は多いです。
システム基盤を改変しよう(してもらおう)と思うより、ちょっとしたアルゴリズムで解決できることに気づけるとスマートですね。
文字列に関するアルゴリズムは他にもたくさんありますので、ぜひご自身でも調べてみてください(参考リンクに掲載)。
以上で、最長共通部分列(LCS)の求め方と、ユニークな検索の実装の説明を終わります。お疲れ様でした。

