

グラフの性質を決める重要な要素の1つに、グラフがサイクルを含むかどうかというものがあります。サイクルは、グラフに関する初歩的な探索(DFS, BFS)を学んだ後に、よく出てくる内容です。
本記事では、グラフの性質を理解する上でサイクルの有無が重要である理由を解説し、サイクルの無いグラフに関する重要な話題をブラウズしてみます。
なお、3章から説明しているDAG, トポロジカルソートについては、私が作成したJupyter Notebookを実行して、ご自身のグラフでご確認いただけます。
グラフがサイクルを含むかどうかが重要な理由は、サイクルの有無は、グラフで表現しようとするデータ(たち)の性質と密接な関係があるからです。
ゲームの局面遷移をグラフで管理する場合を考えます。
次の図は、3目並べのある局面からの遷移を表します。3目並べでは、ゲームの進行に合わせて3×3の盤面が埋まっていくのみで逆戻りしないため、ゲーム中に同じ局面が2度以上現れることはありません。
よって、3目並べの局面遷移を管理するグラフは、サイクルを含まないグラフになると考えられます。
ところが、より複雑なゲームを想定すると、同一局面が2度以上現れる場合はよくあります。以下に、将棋のある局面から考え得る局面遷移を示します。下図では、4手周期で同じ局面が繰り返されていることが分かります。
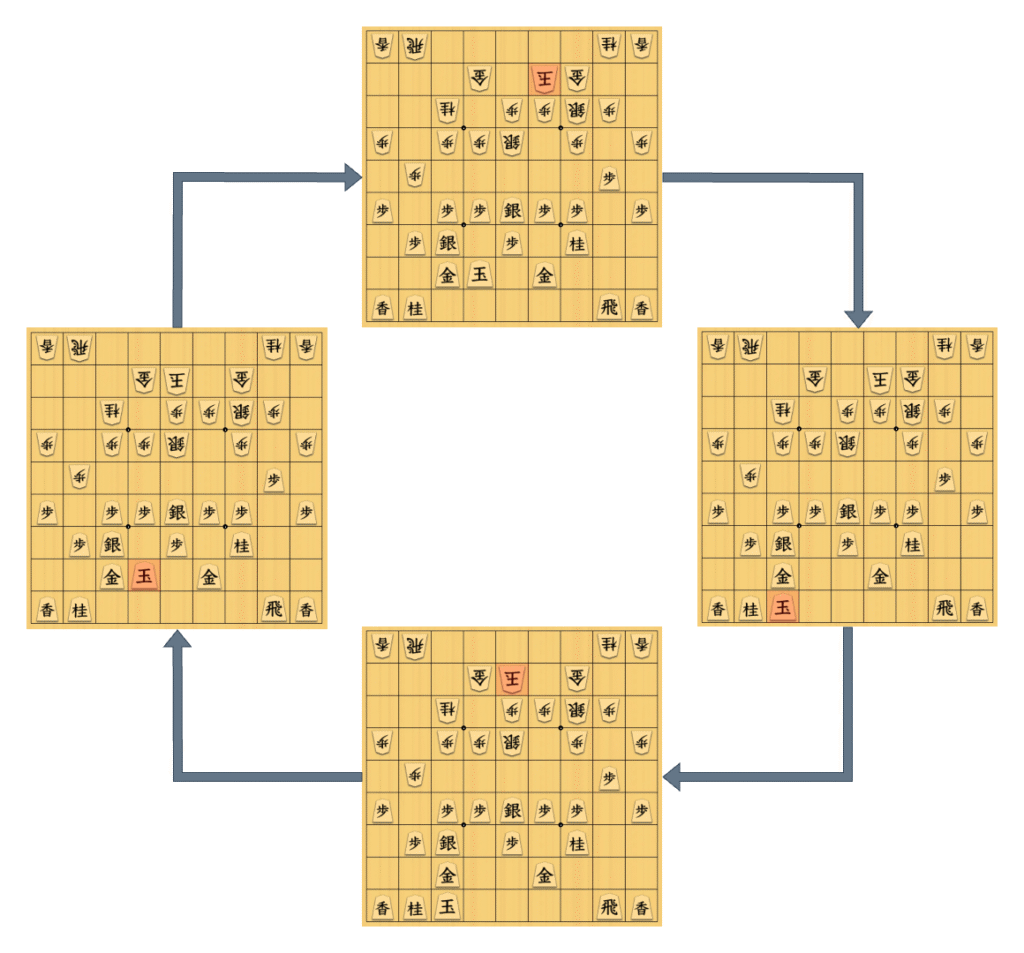
図上の局面から3手後に、再び同一の局面が現れている
また、囲碁のコウと呼ばれる局面では、理論上は、2手周期で同一局面が現れる場面を想定することができます(下図のような2手周期のループは、現実の対局では禁止されています)。
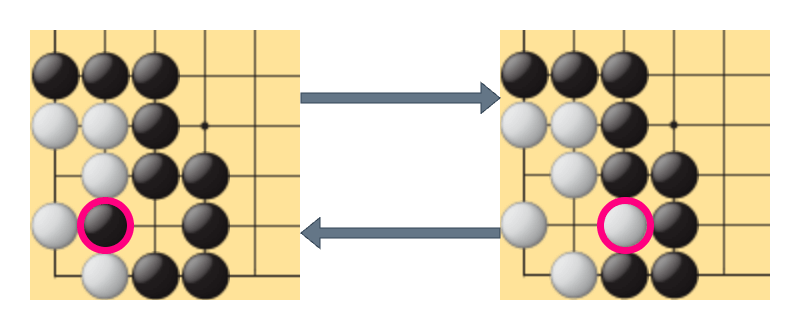
同一局面の出現があり得るゲームの局面遷移を管理するグラフは、必然的にサイクルを含むグラフでなくてはなりません。
また、ゲームAIを想定すると、サイクルの始点(=終点)である局面に着目して
- 過去に出現した同一局面の評価を使用し、計算を省略する
- 過去の探索履歴を利用し、その局面からの探索を省略する
といった措置を取る必要があることも想像できます。
裏を返せば、3目並べのようなゲームのAIにおいては、一度通過した局面の計算結果を捨てても良いということになります。

グラフで表現するデータの性質と、サイクルの有無には密接な関係があるんだね。
交通ネットワークはグラフの身近な利用例であり、道路図や路線図はグラフ表現そのものです。地点をノード、地点間を結ぶ道路や鉄道をエッジとして抽象化していますね。
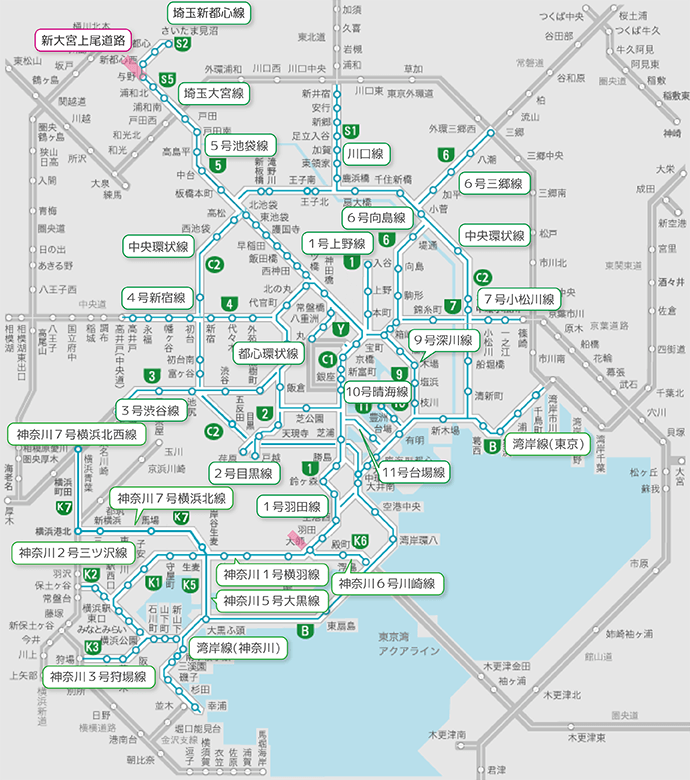
交通ネットワークを管理するグラフは、明らかにサイクルを含む(しかも、たくさん含む)ことがわかりますね。
次に、グラフにサイクルがあってはいけない場合を考えます。
複数のファイル(=モジュール)から構成されるソフトウェアをコンパイルするとき、「どのモジュールがどのモジュールを使用しているか」という依存関係を事前に調べる必要があります。
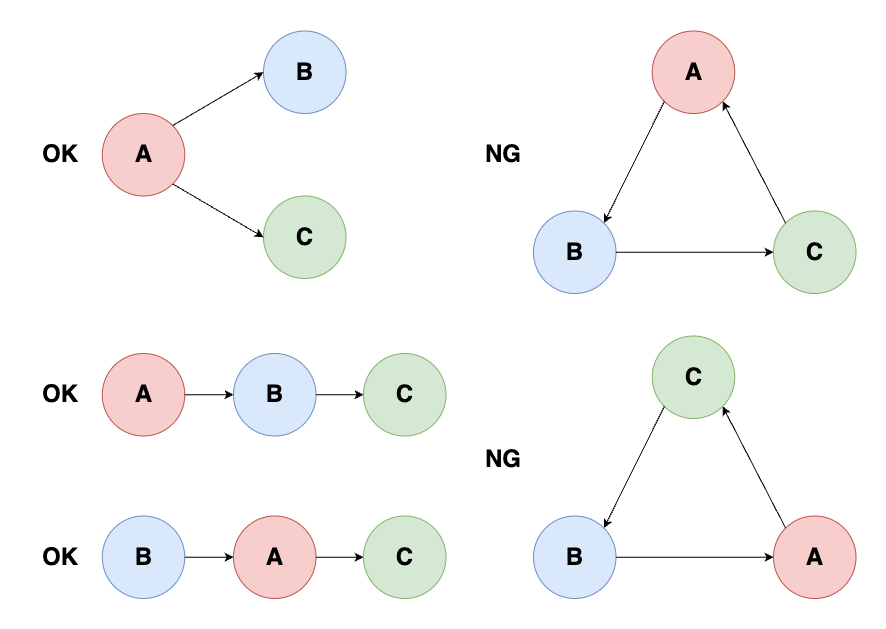
A, B, Cの3つのモジュールから構成されるソフトウェアを考えます。下図は、A, B, Cの依存関係の一例と、対応する有向グラフを示しました。
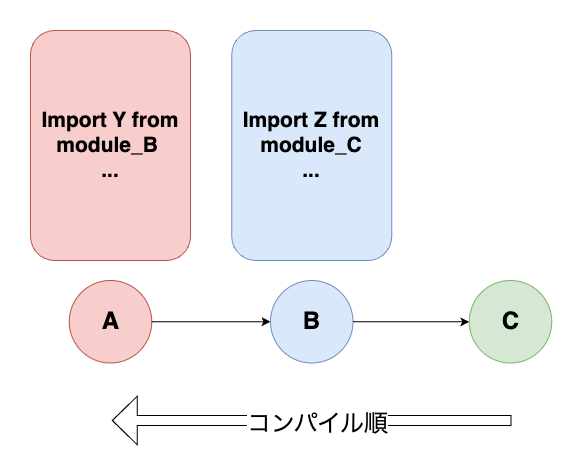
- モジュールAは、プログラム中でモジュールBにあるYを使用している
- モジュールBは、プログラム中でモジュールCにあるZを使用している
という場合、コンパイルする順序は有向グラフを逆向きに辿った順番となり、C -> B -> Aとなります。AはBに依存しており、BはCに依存しているからです。
ところが、うっかり、下図のような依存関係を持つプログラムを書いてしまった場合にはどうなるでしょうか。
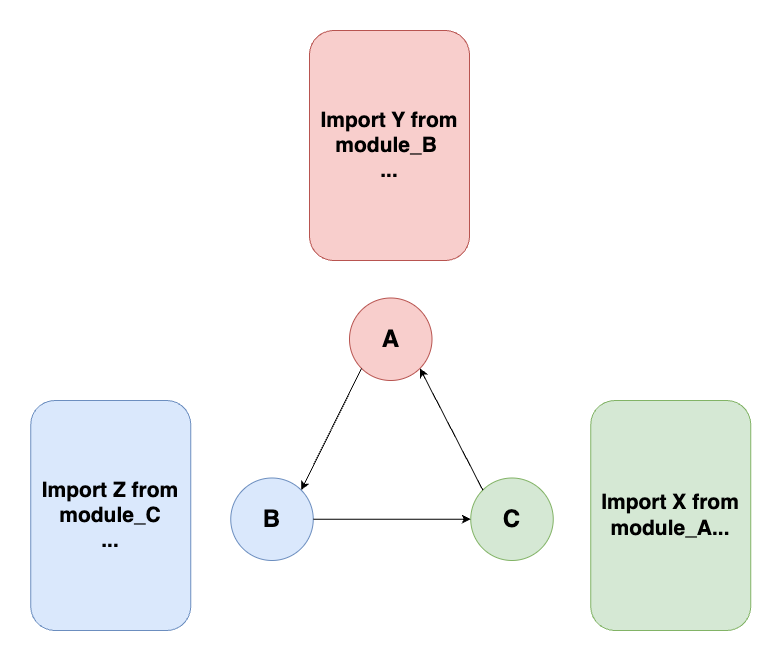
- モジュールAは、モジュールBに書かれたYを使用している
- モジュールBは、モジュールCに書かれたZを使用している
- モジュールCは、モジュールAに書かれたXを使用している
このように互いに循環参照しているモジュール群で構成されるソフトウェアをコンパイルしようとしても、最初にコンパイルすべきモジュールを決めることができません。
モジュール間の依存関係を表現した有向グラフを、依存関係グラフと呼びます。ソフトウェアが正常にコンパイルできるためには、依存関係グラフがサイクルを含まないことが必要です。
依存関係グラフは、サイクルを含んではいけない
C++のビルダーであるCMakeは、ソフトウェアを正しくコンパイルするために、モジュールの依存関係グラフを構築し、依存関係グラフにサイクルが無いことを確認します。仮に、依存関係グラフにサイクルが存在すればコンパイルエラーを起こし、ユーザーに依存関係を解決するように促すのです。
これまで、たった3つのモジュールの依存関係を考えましたが、現実のソフトウェアでは数十〜数百以上のモジュールが存在するのが普通です。

どうやってコンパイル順を決めるかなんて、考えるだけで疲れる。
このような一般の有向グラフに対して、サイクルの有無による性質の違いをはっきりと捉え、正しい処理の順序を整理するための概念が、次章で説明する、DAGとトポロジカルソートです。
一般に、サイクルを含まない有向グラフのことを、有向非巡回グラフ(Directed acyclic graph, DAG)と言い、しばしばDAGと呼称されます。
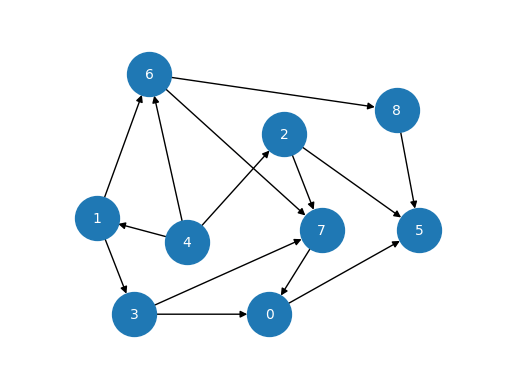
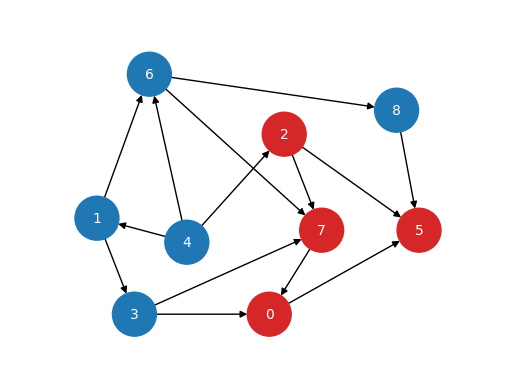
前章の最後に紹介した、8個のノードで構成されるグラフは、実はDAGになっています。

DAGかどうかなんて、見てすぐ分かるのかな。
可視化されたグラフを見ても、DAGかどうかを即座に見分けることは難しいですよね。
グラフの構造を変更せずに、グラフがDAGであることを分かりやすくし、さらに処理すべき順序にノードを整理する(ソートする)方法を、トポロジカルソートと言います。
上図で示したDAGをトポロジカルソートし、トポロジカルソート順が分かるように図示したものが下図になります。
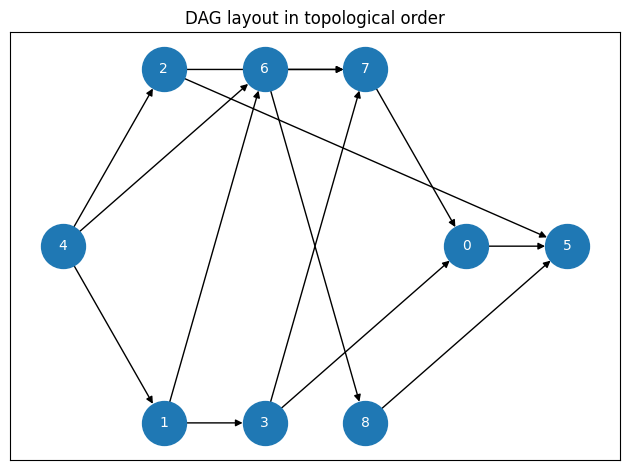
トポロジカルソート順に並べたノードを眺めると、左から右へ向かった参照はあっても、右から左に向かう参照はなく、処理すべき順序が明らかになっています。
前章の例と並べてみると、トポロジカルソートの意味がよく分かります。
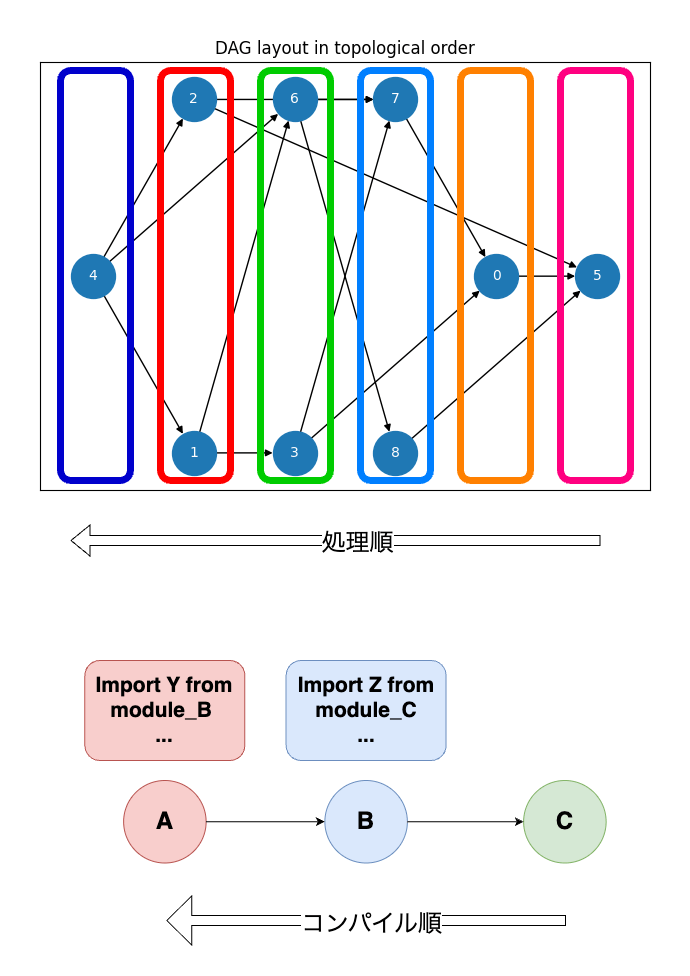
3つのモジュールをC -> B -> Aの順にコンパイルすれば良かったのと同じように、右のレイヤーから順に、ピンク -> オレンジ -> 水色 -> … -> 青色と処理すれば良いことが分かります。
さらに、
同じレイヤーに所属するものは、並列に処理して問題ない
こともわかります。例えば、ノード6(緑)は、ノード7, 8(水色)が両方終了した後に開始しないといけないという順序はあるけれど、同じ緑レイヤーに所属するノード6とノード3は並列処理で構わないわけですね。
一般に、DAG(サイクルを持たない有向グラフ)に対しては、1つ以上のトポロジカルソート順が必ず存在することが証明されており、トポロジカルソート順を求めるアルゴリズムは十分に高速であることもわかっています。
トポロジカルソートするアルゴリズム
トポロジカルソートは、深さ優先探索(DFS)に手を加えることで実装できます。アルゴリズムの詳細は、素晴らしい解説に譲ります。実装は簡単ですので、一度試してみることをおすすめします。
トポロジカルソートは、互いに複雑な依存関係のあるタスクを、ガントチャートに整理する行為に例えられます。ガントチャートでは、Aを完了しなければ開始できないタスクB、があった時、A -> Bの順に左側から並べていきますよね。

ガントチャートに見られるタスク同士の位置関係は、トポロジカルソート順に並べられたグラフを想起させる

ガントチャートとトポロジカルソート順の図を見てみると、類似点がよくわかるぜ。
最後に、ご自身で作成されたグラフの可視化と、トポロジカルソート順をみる簡単なツールを公開していますので紹介します。
DirectedGraphクラスは、インスタンス生成時に隣接リストを受け取り、有向グラフを表すオブジェクトを生成します(隣接リストとは)。
DirectedGraphクラスの.disp_network()メソッドで、作成した有向グラフを表示します。可視化には、PythonライブラリのNetworkXを使用しています。
notebookにあるposは、それぞれのノードを表示する座標です。私が作成したサンプルのDAGを見やすく表示するために設けた変数ですので、使用しないまたは、ご自身で書き換えてご利用ください。
トポロジカルソート順にノードを並べ変えたグラフを可視化するためには、.topological_order_view()メソッドを使用してください。
DirectedGraphクラスには(おまけで)その他に2種類のメソッドが実装されています。
- .can_reach() メソッド:
.can_reach(s, t)で、sからtへ到達できるか判定する - .reachable_nodes_view() メソッド:
.reachable_nodes_view(s)で、sを始点として到達可能なノードを可視化する
以上で、サイクルの有無によるグラフの性質の違いと、サイクルを含まない有向グラフ(DAG)に関する性質、トポロジカルソートの説明を終わります。お疲れ様でした。
隣接リストは、以下で表されるような2次元リストで、グラフを表現する方法です。

以下のグラフを隣接リストで表します。各ノードについて、隣接するノードを列挙します。
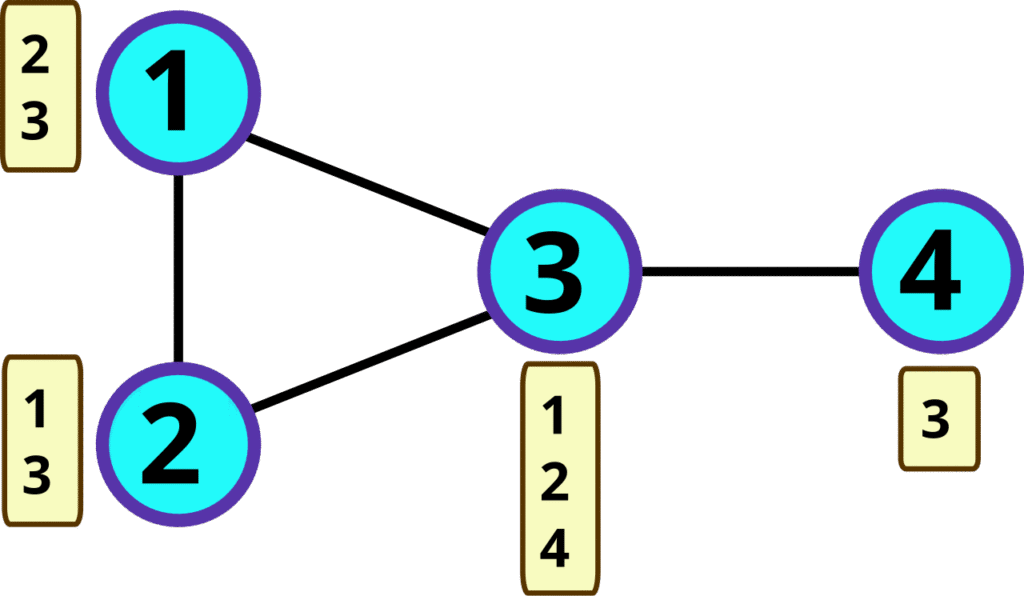
隣接リスト表現は以下のようになります。

