ディープラーニングで、メモリが不足によるプログラムのクラッシュを経験する人は多いと思います。GPU使用時でも、モデル訓練時にVRAM(GPUの専用メモリ)にデータが乗り切らず、
RuntimeError: CUDA out of memory
とRuntimeErrorエラーが出ることはないでしょうか。
Goole社は、自社開発したAIモデル用ASIC(専用回路)であるTPU(Tensor Processing Unit)を、Google Colabで提供しています。
ColabのTPUには無料枠でも大容量メモリが割り当てられているため、ColabのGPUやお手元の環境でメモリ不足に陥る学習を、クラッシュせずにお試しできる可能性があります。
本記事では、TPU環境で学習を実行する実装例を解説します。なお、本記事の内容はGitHubで確認でき、以下のリンクから直接notebookを実行していただくこともできます。

Google ColabでTPUを選択する
Colab環境を開いたら、右上の接続メニューから、「ランタイムのタイプを変更」を選択します。
 接続メニュー→ランタイムのタイプを変更
接続メニュー→ランタイムのタイプを変更
次に、「v2-8 TPU」を選択して保存します。これでTPUを使用した実行環境に切り替わります。
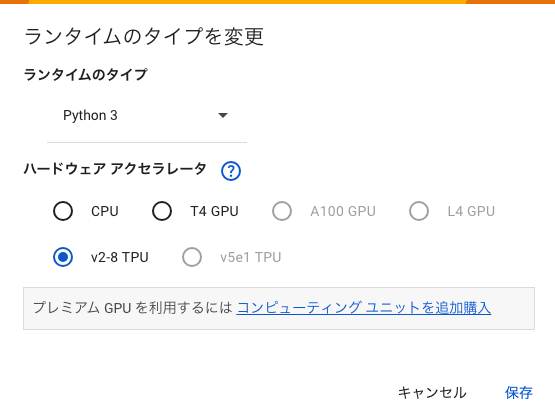 TPUの選択
TPUの選択
v2-8 TPUは、無料枠でも使用することのできるTPUです。表示されるTPUのバージョンは、今後も変更される可能性がありますので、Googleサポート情報などを随時確認してください。
TPUを使用してモデルを学習させる
今回は、実装の詳細については、ソースコードで確認していただくか、以下のColabリンクから直接実行しての確認をお願いします。
次項から、TPUによる学習の要点を説明します。
タスク:CIFAR-10 分類問題
今回モデルにやらせるタスクは、CIFAR-10の10クラス分類問題です。CIFAR-10は、10種類のクラスに分類される60,000個の、サイズ32 x 32のRGB画像から構成されるデータセットです。
 cifar-10データセットからランダムにピックした、25枚の画像データと正解ラベル
cifar-10データセットからランダムにピックした、25枚の画像データと正解ラベル
小さなCNNベースのネットワークを実装し、TPU上でCIFAR0-10を学習させてみます。
高メモリ負荷を再現する設定
CIFAR-10は画像認識入門用のデータセットですが、例えば、MNIST(手書き文字認識)と比較すると画像の複雑性は大きく、データ容量も大きいです。
ハンズオン形式の入門書では、CIFAR-10分類問題の実装と動作確認を行う例は(意外にも)少ないです。なぜなら、
- CIFAR-10で90%以上の精度を出せるモデルは、入門用としては複雑
- 0からの学習させると学習時間が長すぎたり、メモリ不足を起こしたりする
からです。
以上を踏まえつつ、今回は以下の2種類の設定を行い、10〜16GB程度のメモリでは学習できない状態を再現します。
学習の設定
・バッチサイズを500に設定して、一度の(ミニ)バッチ学習に多くのメモリが必要な状態にする
・評価データの損失計算を、評価データ全部で正規化された交差エントロピー誤差で計算する
バッチサイズを大きくすると、学習が安定化する(可能性がある)というメリットがあります。また、学習テクニックとしてバッチサイズを大きくする例もあります。
評価データの損失は、理論的にはバッチに分けて計算する必要が無いですが、メモリ節約のために、バッチサイズごとに計算した損失の合計で近似することがあります。今回は全部まとめて計算します。
PytorchでTPUを使用する実装
TPUを使用する実装の要点3点について、個別に解説します。
torch_xlaライブラリの導入
Colab notebook上で以下を実行し、pytorch_xlaライブラリを導入します。また、torch_xlaと互換性のあるバージョンのPyTorchをインストールします。
{"code":"!pip install torch~=2.5.0 torch_xla[tpu]~=2.5.0 -f https:\/\/storage.googleapis.com\/libtpu-releases\/index.html -f https:\/\/storage.googleapis.com\/libtpu-wheels\/index.html","filename":"","language":"python","id":0}モデルとTensorをTPUに転送する
TPUのメモリは、pythonプログラムが実行されるCPUのメモリと分離されていますので、AIモデルとTensorをTPUメモリに転送しておく必要があります。
 TPU Virtual Machineのアーキテクチャ。
TPU Virtual Machineのアーキテクチャ。
引用元:https://cloud.google.com/tpu/docs/intro-to-tpu?hl=ja
torch_xla.core.xla_model.xmを使用してデバイスを設定し、訓練データと正解ラベル(のTensor)を転送してください。下記のコードの24行目、25行目の部分です。
{"code":"from torch import optim\n# torch_xla\u30e9\u30a4\u30d6\u30e9\u30ea\u306eimport\nimport torch_xla\nimport torch_xla.core.xla_model as xm\n\nrecord_loss_train = []\nrecord_loss_test = []\n\ndef training():\n # XLA\u30c7\u30d0\u30a4\u30b9\u306e\u8a2d\u5b9a\n device = xm.xla_device()\n\n loss_func = nn.CrossEntropyLoss()\n optimizer = optim.Adam(model.parameters())\n x_test, t_test = iter(test_loader).__next__()\n x_test, t_test = x_test.to(device), t_test.to(device)\n\n for epoch in range(15):\n # \u30e2\u30c7\u30eb\u3092\u8ee2\u9001\n model = model.train().to(device)\n loss_train = 0\n for j, (data, target) in enumerate(train_loader):\n # \u8a13\u7df4\u30c7\u30fc\u30bf\u3068\u6b63\u89e3\u30e9\u30d9\u30eb\u3092\u8ee2\u9001\n data = data.to(device)\n target = target.to(device)\n\n y = model(data)\n loss = loss_func(y, target)\n loss_train += loss\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n xm.mark_step()\n\n loss_train \/= (j + 1)\n record_loss_train.append(loss_train)\n\n model = model.eval().to(device)\n y_test = model(x_test)\n loss_test = loss_func(y_test, t_test).item()\n record_loss_test.append(loss_test)\n \n print(f\"Epoch: {epoch}, Loss_Train: {loss_train}, Loss_Test: {loss_test}\")\n\ntraining()","filename":"","language":"python","id":0}TPUもアクセラレータですので、このあたりはCUDAを使用する場合と同様です。
学習ステップを、XLAデバイスに記録する
前項のコードを再掲します。xm_mark_step()を学習ステップごとに実行し、学習ステップが進んだことをXLAデバイスに記録するようにする必要があります。忘れるとエラーになりますので注意してください。
{"code":"def training():\n device = xm.xla_device()\n\n #...\n\n for epoch in range(15):\n model = model.train().to(device)\n loss_train = 0\n for j, (data, target) in enumerate(train_loader):\n # ...\n optimizer.step()\n xm.mark_step()\n\n #...\n \n print(f\"Epoch: {epoch}, Loss_Train: {loss_train}, Loss_Test: {loss_test}\")\n\ntraining()","filename":"","language":"python","id":0}TPUで計算されたデータをCPUに持ってくる
損失や正答率などのグラフ化をする前に、TPUで計算されたTensorをCPUのメモリに持ってくる必要があります。
Tensorの.cpu()メソッドを使用して、データを持ってくるようにしてください。
{"code":"import matplotlib.pyplot as plt\n\n# Fetch tensor from TPU memory\nplt.plot(range(len(record_loss_train.cpu())), record_loss_train.cpu(), label=\"Train\")\nplt.plot(range(len(record_loss_test.cpu())), record_loss_test.cpu(), label=\"Test\")\nplt.legend()\n\nplt.xlabel(\"Epochs\")\nplt.ylabel(\"Error\")\nplt.show()\n\ncorrect = 0\ntotal = 0\nmodel.eval()\ndevice = xm.xla_device()\nfor i, (x, t) in enumerate(test_loader):\n x = x.to(device)\n y = model(x)\n # Fetch tensor from TPU memory\n z = y.cpu()\n correct += (z.argmax(1) == t).sum().item()\n total += len(x)\nprint(\"Accuracy[%]: \", str(correct\/total*100) + \"%\")","filename":"","language":"python","id":0}以上が、学習に必要な計算をTPU上で行うための実装の要点です。ぜひ活用してみてください。お疲れ様でした。
本記事のGithubで公開しているモデルは、メモリのテスト用に私が自作したものです。モデルの複雑性が不足しているため、CIFAR-10で高精度を出すことはできません。高精度を出すモデルを作る場合、VGG, Resnet, GooleNetをベースにより大規模なモデルの構築をお勧めします。
私の実験では、Resnetベースで95%以上の精度を出すことができました。
参考リンク



