

CNNに使用されるGlobal Average Pooling(GAP)の内容と、GAPを使用したネットワークの実装例を紹介します。
本記事の内容はGithubで確認できます。また、以下のリンクから直接、Jupyter Notebookでコードを実行していただけます。
Global Average Pooling(以下、GAP)は、CNNベースのニューラルネットワークに使用される特殊な平均値Poolingです。2014年に提案され(Network In Network)、Resnetなどの有名ネットワークの一部に採用されています。
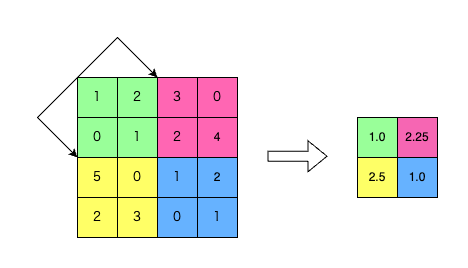
通常の平均値Poolingはあるウィンドウサイズを持ち、ウィンドウをずらしながら領域内の平均値を出力します。図1は、ウィンドウサイズが 2 x 2、ストライド2の平均値Poolingを、4×4の入力データに適用する時の様子です。
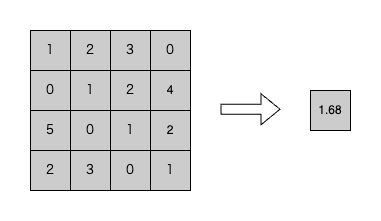
GAPは、入力データのサイズに関係なく、入力データ全部の平均値1つを出力とするシンプルな平均値Poolingです。ウィンドウサイズを持たず、出力は入力データの形状に関係なく1×1になります(図2)。
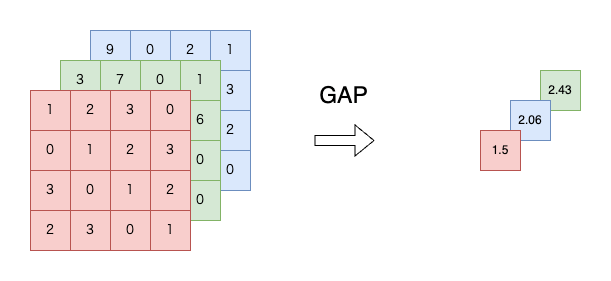
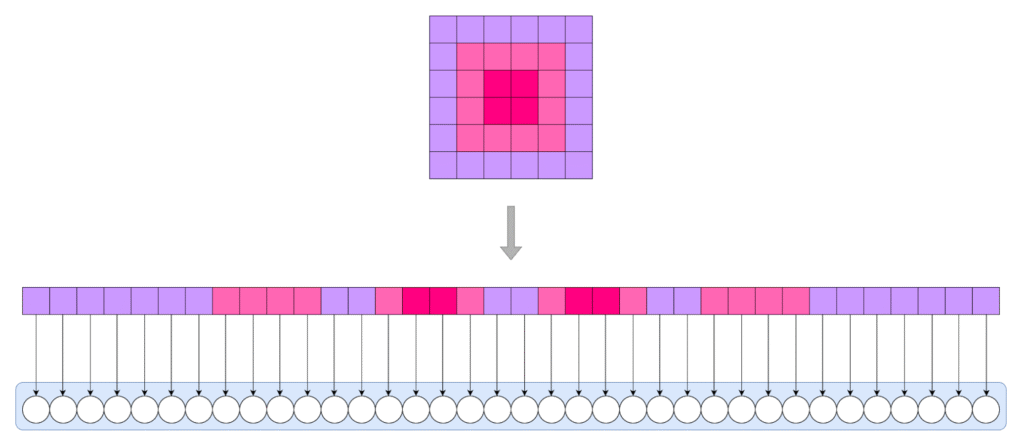
一般のデータに対するGAPは、1チャンネルにつき1つの平均値を出力する処理を行います。下図3のように、形状が(3 x 4 x 4)の入力データにGAPを行うと、出力データ形状は(3 x 1 x 1)になります。
次項は、GAPレイヤーを採用するメリットを説明します。
CNNにGAPレイヤーを採用する最も分かりやすいメリットは、畳み込み層(Convolution Layer)の後に単に全結合レイヤー(Fully Connected Layer)を接続したCNNと比較して、学習パラメータの数を少なくすることが出来ることです。
学習パラメータが多いと学習時間が増加したり、過学習や勾配消失を起こしやすくなったりするため、パラメータを少なくすることは重要です。
冒頭に紹介した通り、GAPはResnetなどの有名ネットワークに採用されています。ここでは、GAPを使用していないVGGとResnetのパラメータ数比較を通して、GAPでなぜ学習パラメータを減少させられるのか具体的に説明します。
VGGは、下図4のように、畳み込みとMax Poolingを繰り返した後、全結合レイヤーに接続して画像分類を行うシンプルなネットワークです。
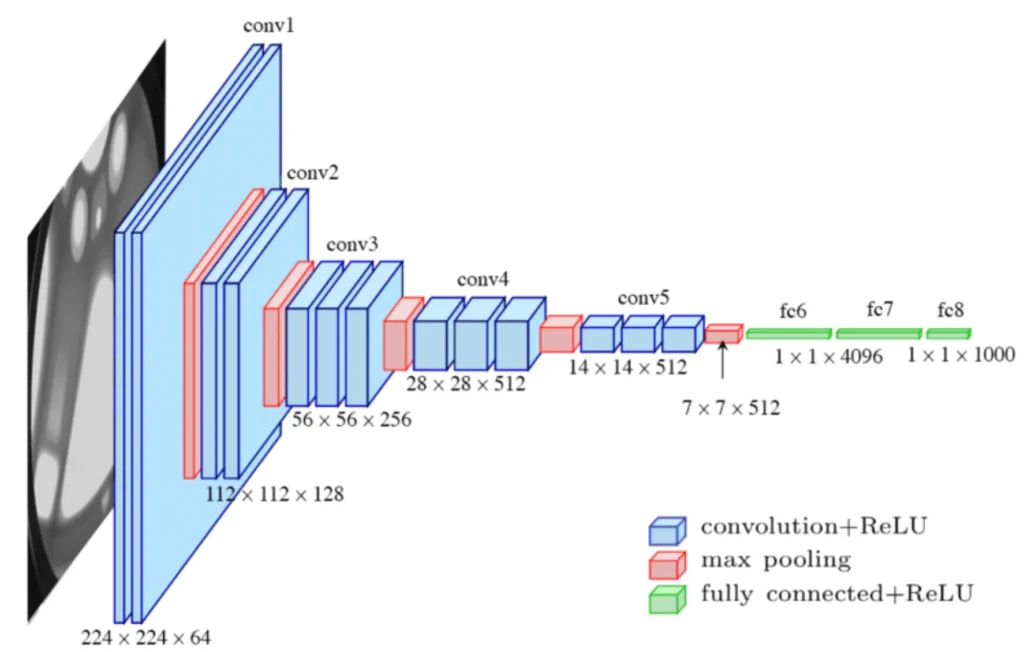
VGGのように、畳み込みの出力を単に全結合層に入力するネットワークでは、畳み込みの出力を全て1次元のベクトルに”延ばした”ものを入力するため、全結合層のパラメータ数が非常に多くなる傾向があります。
下図5は、1チャンネル分のデータを全結合層に入力する模式図です。図4に示したVGG16の場合、畳み込み層の出力は512チャンネルあるため、最初の全結合層のパラメータ数が非常に多くなります。
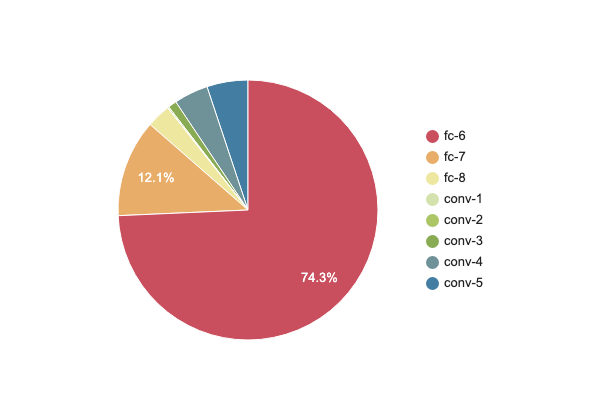
VGG16(※補足)を構成する各レイヤーのパラメータ数が、ネットワーク全体のパラメータ数に占める割合を下図6に示します。VGG16の最初の全結合層のパラメータ数は102,764,544 ~= 102millionで、全体のパラメータ数138,357,544 ~= 138millionの75%弱を占めます。
レイヤー名は図4のネットワーク模式図に合わせている。
Resnetでは、全結合層の直前にGAPレイヤーを採用しています。GAPを取ると出力されるベクトルの要素数はチャンネル数になるため、全結合層のニューロン数を少なくできます。
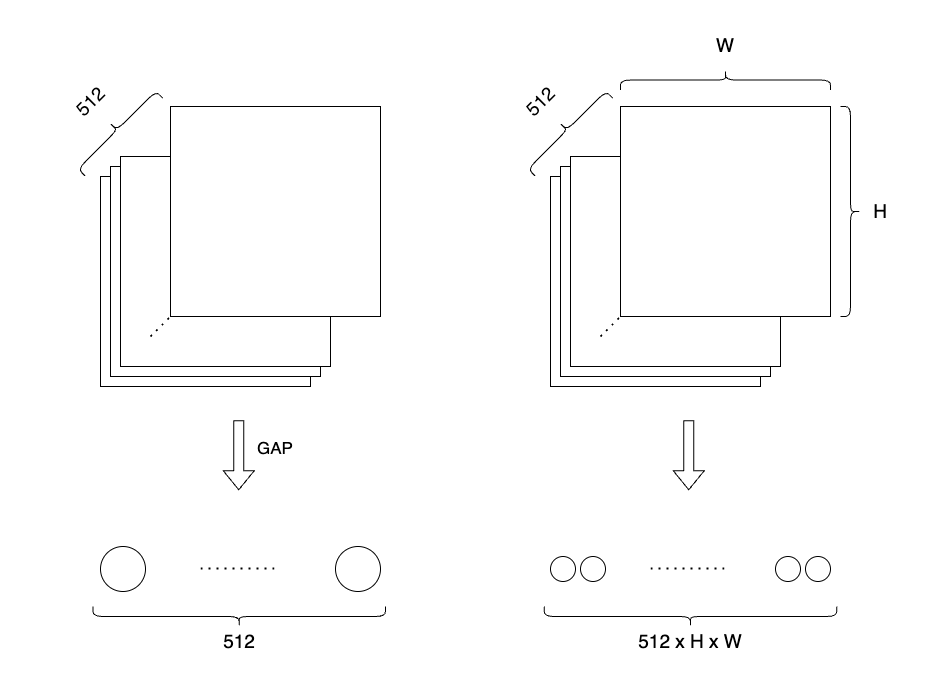
下図7は、512チャンネルのデータが入力される全結合層に必要なニューロン数を、GAPの有無で比較した概念図です。GAPを取らないネットワークでは、512 x H x Wの数だけニューロンが必要ですが、GAPを取るネットワークでは512個のニューロンで済みます。
以上が、GAPレイヤーを使用することで学習パラメータを減少させることの出来る原理です。
本記事でレイヤーごとのパラメータ数を示しているVGG16は、元論文のTable 1: ConvNet configurationsに記載されているネットワークDを対象としています。PyTorch, Kerasに実装されているモデルとほぼ同一ですが、細部の実装においては異なる可能性があります
Pytorchに実装されたResnet50とVGG16のパラメータ数を比較すると、Resnet50のパラメータ数は25.6M(25.6million)で、VGG16の5分の1以下です。
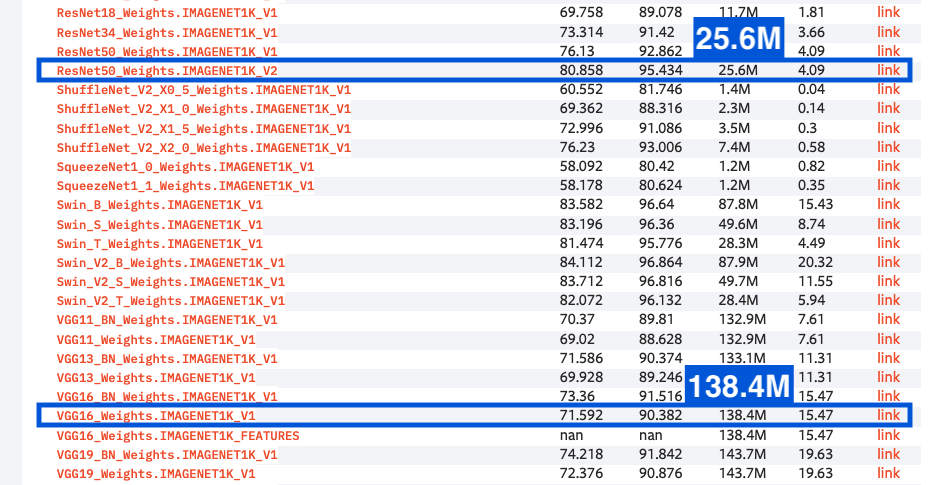
引用元:Models and pre-trained weights
詳細は元論文(Deep Residual Learning for Image Recognition)に譲りますが、Resnet50はVGG16よりずっと畳み込み層の数が多い「ディープな」ネットワークです。にも関わらず、Resnet50のパラメータ数がVGG16よりも少ないのは、全結合層のパラメータ数の違いによるところが大きいです。
Resnetは、ILSVRC2015で優勝したCNNベースの有名ネットワークです。スキップ構造により多層の畳み込み層で生じうる課題を克服しています。
ところで、GAPレイヤーによる学習パラメータ数の減少により、モデルの表現力が不足し性能に問題が生じないでしょうか?結論から述べると、GAPレイヤーの有無による性能の変化は元論文で議論されており、正しい使い方をしていれば心配ありません。
次章では、GAPレイヤーを使用した小さなCNNをMNISTデータセットの分類問題に適用し、性能が出ることを確認してみます。
GAPを使用したCNNを、MNISTの分類問題に適用してみます。モデルの実装や学習・評価の詳細に関して、PyTorchによる実装がGithubのnotebookにありますので参照をお願いします。また、以下からGoogle Colabを開いて実行することもできます。
以下では実装のポイントを説明します。
本記事で実装したネットワークの模式図を下図9に示します。全結合層の前にGAPレイヤーを採用した部分以外は、VGGをベースにしています。

Kerasをご使用の方は、専用のGlobalAveragePooling2Dレイヤーがありますので使用してください。
PyTorchにはGAP用のレイヤーは実装がありません。平均値Poolingを行うAdaptiveAvgPool2dをGAPとして使用します。
AdaptiveAvgPooling2Dは、AdaptiveAvgPooling2D((h, w))のように出力サイズをタプルで指定すると、出力サイズのデータが(h, w)になるように自動的にウィンドウサイズやストライド・パディングなどのパラメータを設定して平均値Poolingを行なってくれるレイヤーです。
GAPは出力サイズが(1, 1)の平均値Poolingですから、AdaptiveAvgPooling2D((1, 1))と指定しましょう。h = wの時には、AdaptiveAvgPooling2D(1)のような省略表記が可能です。
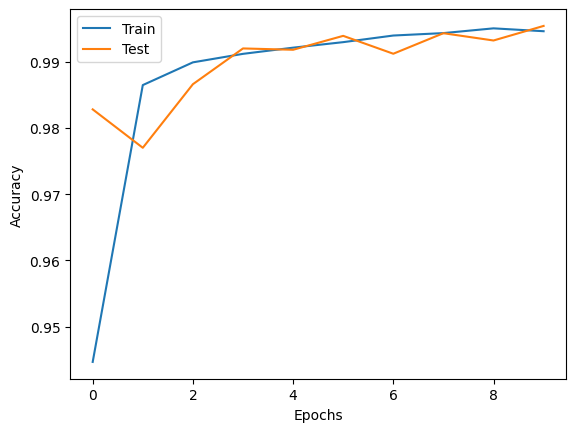
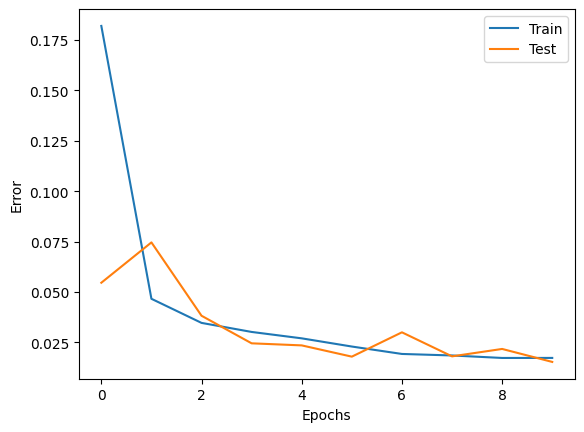
以下の図10に、エポックごとの精度と損失の推移をまとめて示します。60,000個の訓練データに対して、学習を10エポック行い、10エポックの時点で正答率は99%を超えました。
(MNISTは非常に簡単な問題ではありますが、)GAPを使用したネットワークがうまく機能することを手を動かして確認することができました。
ハイパーパラメータ等、条件の詳細はGithubの参照をお願いします。本記事では、以下の表1に簡潔に記載するに留めます。
| 訓練データ数 | 60,000 |
| テストデータ数 | 10,000 |
| バッチサイズ | 100 |
| エポック数 | 10 |
| 評価方法 | ホールドアウト法 |
以上で、CNNにおけるGlobal Average Poolingの使用方法と実装の解説を終わります。お疲れ様でした。
- Network In Network
- Very Deep Convolutional Networks for Large-Scale Image Recognition
- Deep Residual Learning for Image Recognition
- ImageNet Large Scale Visual Recognition Challenge 2015 (ILSVRC2015)
- Models and pre-trained weights
- GlobalAveragePooling2D layer | Keras Documentation
- AdaptiveAvgPool2d — PyTorch 2.5 documentation
- MNIST — Torchvision main documentation – Datasets
- ResearchGate.net

