

Hackerrankは、世界中のエンジニアが共通のプログラミング問題に挑戦できるサービスで、問題を解いたスコアを競ったり、コードテストを受験して証明書を発行したりできます。
コードテストの準備用として用意されている問題集(Prepare)は、その場でコードの実行結果を確認できるため「手を動かしながら」各分野の基本を身につけるのに最適です。
本記事では、データ操作言語SQLのPrepareに登録されている難易度Mediumの16問の全問解答例を問題翻訳付きで掲載します。
答え合わせ・問題に詰まった時に活用してください。
本記事のSQLクエリは、Oracleで動作確認(提出)を行なっています。大半のコードは、Oracleに依存しない書き方になっています。
難易度Mediumは、データ整形の基本テクニックや、複数のテーブルからデータを集める方法を学べるレベルです。
いきなりBST(Binary Search Tree, 二分探索木)が出てきて戸惑う人がいるかと思いますが、問題を解くためにはBSTの知識は必要ありませんので、気負わずいきましょう。
ある木構造に対応したBSTテーブルが与えられます。
木構造をテーブルとして表すためには、各ノードの番号と、その親ノードの番号の対応を1行ごとに保存しておけば良さそうです。
例えば、以下のテーブルは次のような木構造に対応します。
| N(Node, ノードの番号) | P(Parent, 親ノードの番号) |
|---|---|
| 1 | Null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
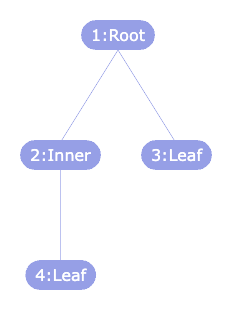
与えられたBSTテーブルから、各ノードが木構造のどの位置にあるのかを復元し、3種類に分類した結果を出力してください。
- Root : 親ノードを持たない、木構造の一番上のノード
- Inner : 親ノードと子ノードを両方持つ中間ノード
- Leaf : 親ノードを持っているが子ノードを持たない、末端(葉)ノード
1 Root
2 Inner
3 Leaf
4 LeafCASE式で以下の分岐を記述します。
- “P”カラムを参照し、親ノードが無かったらRootに決定する
- 親ノードを持つノードに関しては、自身を親ノードとする他のノードがあればInner、無ければLeafに決定する
内容は難しくありませんが、出力の並び替え(ソート)など、細かい要求に気を配る必要があります。
名前と職業の対応が保存されたOCCUPATIONSテーブルが1つ与えられます。
職業はProfessor(教授)、 Actor(俳優)、 Doctor(医師)、 Singer(歌手)のいずれかであり、他の値はテーブルにはありません。
| Name | Occupation |
|---|---|
| Amanda | Professor |
| Mike | Actor |
| Mary | Doctor |
| Olivia | Doctor |
| Jane | Actor |
| Samansa | Professor |
| Adam | Singer |
| Tom | Singer |
| Bob | Actor |
OCCUPATIONSテーブルのデータに、以下の2つの操作を行って出力してください。
- 各職業は頭文字一文字に変換し、Amanda(P)のように「名前(頭文字)」の形式で全員出力する
- 各職業何人居るか集計し、名前の後に文章として4行出力する
文字列の変換と基本の集計処理なので難しくはありませんが、出力の並び替えに注意しましょう。
- 「名前(頭文字)」の出力は、名前のアルファベット順に並び替える
- 集計結果は人数の降順で並び替え、人数が同じ職業が2つ以上あったら、職業のアルファベット順に並び替える
- 集計結果に表示される職業名は全て小文字で表示し、複数形で表記する
形式:There are a total of [occupation_count] [occupation]s
Adam(S)
Amanda(P)
Bob(A)
Jane(A)
Mary(D)
Mike(A)
Olivia(D)
Samansa(P)
Tom(S)
There are a total of 3 actors.
There are a total of 2 doctors.
There are a total of 2 professors.
There are a total of 2 singers.職業名はSELECT句内でCASE式を使って頭文字1文字に変換し、名前のアルファベット順で並び変えます。
GROUP BY句で行った人数の集計結果を後に続けます。集計時にも、職業名の小文字変換と並び替えが必要で、やや煩雑なので注意を払いましょう。
名前と職業についての集計という意味では前問(THE PADS)と同じですが、出力の形式が全く違うので別の問題として考えましょう。
名前と職業の対応を表す以下のテーブル1つが与えられます。
| Name | Occupation |
|---|---|
| Amanda | Professor |
| Mike | Actor |
| Mary | Doctor |
| Olivia | Doctor |
| Jane | Actor |
| Samansa | Professor |
| Adam | Singer |
| Tom | Singer |
| Bob | Actor |
OCCUPATIONSテーブルの人物を職業ごとに分類し、同じカラム(列)に同じ職業の人物の名前が並ぶように出力してください。
さらに、出力について以下の要求があります。
- 列の順番は、左から順に、Doctor→Professor→Singer→Actorにする
- 全部の職業で出力される行数が同じになるように出力を整形する。名前が埋まらないところはNULLを出力する
- 同じ職業の人物の出力順は名前のアルファベット順にする
本問に関しては、出力を先に見た方がわかりやすいかも知れません。
Mary Amanda Adam Bob
Olivia Samansa Tom Jane
NULL NULL NULL Mike解答例はやや長いです。 ROW_NUMBERで集計することで、「各職業に所属する人の1番目、2番目、…」を取得しています。
SQLで算術演算を使用する問題です。
駅名を保存したSTATIONテーブルが1つ与えられます。STATIONテーブルには、各駅の位置が緯度と軽度で与えられています。
| ID | CITY(都市) | STATE(州) | LAT_N(北緯) | LONG_W(西経) |
|---|---|---|---|---|
| 824 | Loma Mar | CA | 48.69788572 | 130.53935410 |
| 478 | Tipton | IN | 33.54792701 | 97.94286036 |
| 619 | Arlington | CO | 75.17993079 | 92.94615894 |
| 711 | Turner | AR | 50.24380534 | 101.45801630 |
STATIONテーブルの中から、「最も大きい北緯と最も小さい北緯の差」と「最も大きい西経と最も小さい西経の差」を足し合わせた値(マンハッタン距離)を求めてください。
出力に対して、問題には以下の要求があります。
- マンハッタン距離の計算結果は、最後に四捨五入して小数点4桁に丸める
サンプルデータ中で
サンプルデータ中で最も大きい北緯は75.17993079、最も小さい北緯は33.54792701です。
最も大きい西経は130.53935410、最も小さい西経は92.94615894です。
よって、(75.17993079 – 33.54792701)+ (130.53935410 – 92.94615894)を小数点5桁目で四捨五入した結果になります。
79.2252素直に実装しましょう。この問題に解答するために、都市名や駅IDは全く不要であることがわかります。
Weather Observation Station 18に引き続き、SQLで算術演算を使用する問題です。
駅名を保存したSTATIONテーブルが1つ与えられます。STATIONテーブルには、各駅の位置が緯度と軽度で与えられています。
| ID | CITY(都市) | STATE(州) | LAT_N(北緯) | LONG_W(西経) |
|---|---|---|---|---|
| 824 | Loma Mar | CA | 48.69788572 | 130.53935410 |
| 478 | Tipton | IN | 33.54792701 | 97.94286036 |
| 619 | Arlington | CO | 75.17993079 | 92.94615894 |
| 711 | Turner | AR | 50.24380534 | 101.45801630 |
STATIONテーブルの中の最も大きい北緯X1, 最も大きい西経Y1、最も小さい北緯X2、最も小さい西経Y2とします。
地点A(X1, Y1)地点B(X2, Y2)とした時に、地点Aと地点Bの距離を求めてください。
出力に対する要求として、以下の条件があります。
- 距離の計算結果は、最後に四捨五入して小数点4桁に丸める
最も大きい北緯が75.17993079、最も小さい北緯は33.54792701です。
最も大きい西経が130.53935410、最も小さい西経は92.94615894です。
地点A(75.17993079, 130.53935410)で、地点B(33.54792701, 92.94615894)になり、A, B間の距離が答えになります。
56.0934素直に実装しましょう。この問題に解答するために、都市名や駅IDは全く不要であることがわかります。
SQLに用意されている、統計値を出力する関数を使用する問題です。
駅に関する情報を保存したSTATIONテーブルが1つ与えられます。
STATIONテーブルには、各駅がある都市・州・駅の緯度と軽度が与えられています。
| ID | CITY(都市) | STATE(州) | LAT_N(北緯) | LONG_W(西経) |
|---|---|---|---|---|
| 824 | Loma Mar | CA | 48.69788572 | 130.53935410 |
| 478 | Tipton | IN | 33.54792701 | 97.94286036 |
| 619 | Arlington | CO | 75.17993079 | 92.94615894 |
| 711 | Turner | AR | 50.24380534 | 101.45801630 |
STATIONテーブルに含まれる北緯の中央値(メディアン)を小数点4桁に四捨五入して出力してください。
上記のSTATIONテーブルのデータは4個ですから、北緯の2番目に大きい値と3番目に大きい値の平均値が中央値(メディアン)になります。
49.4708素直に実装しましょう。STATIONテーブルのうち使用するデータはLAT_Nのみです。
Oracleでは中央値を直接求めるMEDIANがありますので、これを利用します。
2つのテーブルを使用した集計を行う問題です。
2つのテーブルが与えられます。
- Studentsテーブル:ある試験に関する生徒の点数を記録したテーブル
- Gradesテーブル:点数と成績(等級)の対応を定めているテーブル
| ID | Name | Marks |
|---|---|---|
| 1 | Julia | 88 |
| 2 | Samansa | 68 |
| 3 | Maria | 99 |
| 4 | Scarlet | 78 |
| Grade(等級) | Min_Mark | Max_Mark |
|---|---|---|
| 1 | 0 | 9 |
| 2 | 10 | 19 |
| 3 | 20 | 29 |
| 4 | 30 | 39 |
| 5 | 40 | 49 |
| 6 | 50 | 59 |
| 7 | 60 | 69 |
| 8 | 70 | 79 |
| 9 | 80 | 89 |
| 10 | 90 | 100 |
Gradesテーブルに定められた基準に従って生徒の成績を決定し、出力してください。
出力に対する要求は以下です。
- 出力は3列で、左から順にName(名前)→ Grade(等級)→Score(点数)にする
- Gradeが8より小さい生徒については、名前の代わりにNULLと表示する
- 出力はGradeが高い方から出力し、同じGradeの生徒は名前のアルファベット順にソートする
Maria 10 99
Julia 9 88
Scarlet 8 78
NULL 7 68問題への解答に限っては、Gradesテーブルを使用しなくても正答できますが、Gradesテーブルが変更になるとクエリが使用できなくなってしまいます。
SQLクエリの中でGradesテーブルを利用しましょう。
多くのテーブルのデータを合わせて、条件を満たすデータの絞り込みを行う問題です。
コーディングコンテストに関する、以下の4つのテーブルが与えられます。
- Hackersテーブル:コンテスト参加者のIDと名前を保存しているテーブル
- Difficultyテーブル:どの難易度の問題に正答したら何点もらえるかを定めているテーブル
- Challengesテーブル:出題された問題のID、問題作成者のID、問題の難易度の対応を保存した問題リスト
- Submissionsテーブル:解答の提出ID、提出者のID、提出対象の問題ID、得点を保存した提出履歴

問題文が複雑すぎて何したらいいかよく分からないよ。疲れた

注意したいところをまとめたから、そこに集中すると見通しが良くなるぜ。
- コンテスト作成者は問題を解く(提出する)側にも、問題作成者にもなり得る
- 問題に正答したら、Difficultyテーブルで定められている満点がもらえる
- 正答で無い場合にも部分点が存在し、得点が0になるとは限らない
| hacker_id | name |
|---|---|
| 11111 | Mary |
| 22222 | Bob |
| 33333 | Tom |
| difficulty_level(難易度) | score(得点) |
|---|---|
| 1 | 20 |
| 2 | 30 |
| 3 | 40 |
| challenge_id | hacker_id(作成者のID) | difficulty_level |
|---|---|---|
| 100 | 22222 | 1 |
| 200 | 11111 | 2 |
| 300 | 22222 | 3 |
| 400 | 33333 | 3 |
| submission_id | hacker_id(回答者のID) | challenge_id | score |
|---|---|---|---|
| 5555 | 11111 | 100 | 20 |
| 6666 | 11111 | 300 | 40 |
| 7777 | 22222 | 200 | 30 |
| 8888 | 33333 | 100 | 4 |
2つ以上の異なる問題に正答したユーザーを検索して、hacker_idとname(名前)を出力してください。
かなり煩雑ですので、提出履歴が記録されているSubmissionsテーブルから愚直に分析してみましょう。
| submission_id | hacker_id(回答者のID) | challenge_id | score |
|---|---|---|---|
| 5555 | 11111 | 100 | 20 |
| 6666 | 11111 | 300 | 40 |
| 7777 | 22222 | 200 | 30 |
| 8888 | 33333 | 100 | 4 |
提出は4回あるので、順に見てみます。
- haker11111(Mary)は問題100に挑戦し、20点貰った。
問題リスト(Challengesテーブル)を見ると問題100は難易度1である。
Diffycultyテーブルを見ると難易度1の問題の得点は20だから、Maryの得点はこの問題のフルスコアだった。
→ Maryは問題100に挑戦し、フルスコアをもらっている - 同様に考えると、Maryは問題300にも挑戦し、フルスコアをもらっている
- 同様に考えると、hacker22222(Bob)は問題200に挑戦し、フルスコアをもらっている
- 同様に考えると、hacker33333(Tom)は問題100に挑戦したが、得点は4であり、フルスコアではない
以上より、2つ以上の異なる問題に正答したユーザーはMaryだけなので、Maryのidと名前を出力すれば正解です。
11111 Mary各ユーザーの正答数(満点を獲得した問題数)を調べるためには、4つ全てのテーブルのデータが必要です。
下記の実装では、一旦必要な情報を全部集めたビューを作成し、ビューからデータを抽出するという2段階を踏んでいます。
Top Competitorと同じくプログラミングコンテストを題材とした問題で、複数のテーブルから集計処理を行う問題です。
以下の2つのテーブルが与えられます。
- Hackersテーブル:コンテスト参加者のID、名前を保存したテーブル
- Submissionsテーブル:解答の提出ID、提出者のID、提出した問題ID、得点を保存した提出履歴テーブル
| hacker_id | name |
|---|---|
| 11111 | Mary |
| 22222 | Bob |
| 33333 | Tom |
| 44444 | John |
| submission_id | hacker_id(提出者のID) | challenge_id | score |
|---|---|---|---|
| 5555 | 11111 | 100 | 20 |
| 6666 | 11111 | 300 | 40 |
| 7777 | 22222 | 200 | 30 |
| 8888 | 33333 | 100 | 4 |
| 9999 | 33333 | 100 | 20 |
| 12345 | 44444 | 200 | 0 |
| 54321 | 44444 | 300 | 0 |
各参加者がプログラミングコンテストで得た総得点を集計し、参加者のID、名前、総得点を出力して下さい。
集計の際に、以下のことに注意しましょう。
- 同じ問題に何回も提出できる
- 同じ問題に複数回提出があった場合、一番高い得点で評価する
同じ問題に対しての得点を重複して計算すると、総得点が実際のスコアより大きくなってしまいます。
また、問題の出力に対しては以下の要求があります。
- 総得点が0の参加者は、出力から除外する
- 参加者は総得点の大きい順に並べて出力する。
- 総得点が同じ参加者が複数いたら、IDが小さい順(昇順)に出力する。
例に挙げているSubmissionsテーブルを再掲します。
| submission_id | hacker_id(回答者のID) | challenge_id | score |
|---|---|---|---|
| 5555 | 11111 | 100 | 20 |
| 6666 | 11111 | 300 | 40 |
| 7777 | 22222 | 200 | 30 |
| 8888 | 33333 | 100 | 4 |
| 9999 | 33333 | 100 | 20 |
| 12345 | 44444 | 200 | 0 |
| 54321 | 44444 | 300 | 0 |
- hacker11111(Mary)の総得点は、20+40 = 60
- haker22222(Bob)の総得点は、30
- hacker33333(Tom)は問題100に2回挑戦しており、得点は高い方の20点。
他の問題には提出していないので総得点は20 - hacker44444(John)は問題200と問題300の2問に挑戦しているが、どちらも得点が0のため、出力から除外する
出力は以下のようになります。
11111 Mary 60
22222 Bob 30
33333 Tom 20Hackersテーブルは、hakcker_idからname(名前)を引っ張ってくるためだけに利用します。
集計処理に関してはSubmissionsテーブルのみ考えれば良いことが分かると、見通しが良くなります。
Top Competitors, Contest Leaderboardと同じく、プログラミングコンテストを題材にした問題です。
複数テーブルからの集計を行います。
プログラミングコンテストに出題される問題の作成に関して、以下の2つのテーブルが与えられます。
- Hackersテーブル:コンテスト出題者のIDと名前を保存しているテーブル
- Challengesテーブル:問題のIDと問題作成者のIDの対応を保存した、問題の作成履歴
| hacker_id | name |
|---|---|
| 11111 | Mary |
| 22222 | Bob |
| 33333 | Tom |
| 44444 | John |
| challenge_id | hacker_id(作成者のID) |
|---|---|
| 100 | 11111 |
| 200 | 11111 |
| 300 | 22222 |
| 400 | 22222 |
| 500 | 33333 |
| 600 | 44444 |
各出題者が何問問題を作成したかを集計し、作成者のID、名前、作成数を出力してください。
問題の出力に対しての要求が少しトリッキーなので注意しましょう。
- 出力は問題作成数が多い人から順に並べる。(ルール1)
- 問題作成数が同じ出題者が複数居たら、全員出力から除外する。(ルール2)
- ルール2で除外される出題者の問題作成数が、集計結果の中で最も多い場合に限り、出力に全員表示する。(ルール3)
- ルール3により出力される出題者たちは、IDの若い順(IDの昇順)にソートする
Challengesテーブルを再掲します。
| challenge_id | hacker_id(作成者のID) |
|---|---|
| 100 | 11111 |
| 200 | 11111 |
| 300 | 22222 |
| 400 | 22222 |
| 500 | 33333 |
| 600 | 44444 |
- hacker11111(Mary)とhacker22222(Bob)はともに2問づつ作成している。
- hacker33333(Tom)とhacker44444(John)はともに1問ずつ作成している。
- TomとJohnは作問数が同じため出力から除外する。
- MaryとBobは作問数が同じだが、2問は集計結果の中で最も多いため、2人とも出力する。
11111 Mary 2
22222 Bob 2煩雑なルールのために、分岐が必要になってきます。
ハリーポッターに関する問題です。題意がやや読み取りづらい問題ですが、見た目より簡単です。
魔法の杖に関する、以下の2つのテーブルが与えられます。
- Wandsテーブル:杖のID、コード(杖のカテゴリ)、値段、魔力の強さが保存された杖の販売リスト
- Wands_Propertyテーブル:杖のコード、杖の年齢、杖が邪悪かどうか(0 or 1)の対応を保存したテーブル
杖のコードは、杖の年齢と、杖が邪悪かどうかの2つを決めるカテゴリのようなものです。
例えば杖A, 杖Bが同じコードであれば、杖A,杖Bは年齢が同じであり、一方が邪悪なら他方も邪悪ということになります。
| id | code | coins_needed | power |
|---|---|---|---|
| 1 | 4 | 3000 | 8 |
| 2 | 3 | 9000 | 3 |
| 3 | 3 | 7000 | 10 |
| 4 | 1 | 700 | 8 |
| 5 | 2 | 6000 | 2 |
| code | age | is_evil(1だと邪悪) |
|---|---|---|
| 1 | 45 | 0 |
| 2 | 40 | 0 |
| 3 | 4 | 1 |
| 4 | 20 | 0 |
ハーマイオニーが決めた以下のルールに基づいて、購入の優先順位の高い杖から順に杖のID、年齢、値段、魔力の強さを出力してください。
- 邪悪(is_evil = 1)な杖は購入できない
- 邪悪でない杖のうち、魔力の高い杖を優先する
- 魔力が同じなら、年齢が高い杖を優先する
- 魔力と年齢が同じ杖が複数あったら、値段が一番安い杖のみ購入リストに加える
4 45 700 8
1 20 3000 8
5 40 6000 2魔力と年齢が同じでf値段が高い杖を出力から削除するために、相関サブクエリを用いています。
ここまでの問題が解けていれば簡単な問題です。
以下の3つのテーブルが与えられます。
- Studentsテーブル:人物のIDと名前の対応が保存されたテーブル
- Friendsテーブル:それぞれの人物と、友達のIDが保存されたテーブル
- Packagesテーブル:人物のIDと、その人の給与が保存されたテーブル
| ID | Name |
|---|---|
| 1 | Ashley |
| 2 | Samantha |
| 3 | Julia |
| 4 | Scarlet |
| ID | Friend_ID |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 1 |
| ID | Salary |
|---|---|
| 1 | 15.20 |
| 2 | 10.06 |
| 3 | 11.55 |
| 4 | 12.12 |
自身より友達の方が給与が高いような人物の名前を、友達の給与が低い順(昇順)にソートして出力してください。
ただし、データ中に同じ給与の人物が2人以上含まれないことが保証されています。
Samantha(Friend_ID = 3), Julia(Friend_ID = 4), Scarlet(Friend_ID = 1)の順に出力されます。
Samantha
Julia
Scarletサブクエリを活用して解答すれば比較的容易です。
複数のテーブルの集計作業を行う問題です。見た目より簡単な問題です。
会社組織に関するテーブルが与えられます。
テーブルには複数の会社組織の情報が混在して与えられますが、役職名と役職同士の関係は全ての会社に共通で、以下の通りになっています。
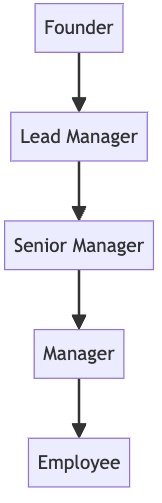
5つの役職それぞれについての情報が、5つのテーブルで与えられます。
- Companyテーブル:会社IDと、その会社のFounder(設立者)の名前の対応が保存されたテーブル
- Lead_Managerテーブル:会社IDと、その会社に所属するLead ManagerのIDの対応が保存されたテーブル
- Senior_Managerテーブル:会社ID、Senior_ManagerのID、上司であるLead ManagerのIDが保存されたテーブル
- Managerテーブル:会社ID、ManagerのID、上司のSenior Manager・Lead ManagerのIDが保存されたテーブル
- Employeeテーブル:会社ID、EmployeeのID、上司のManager・Senior Manager・Lead ManagerのIDが保存されたテーブル
それぞれのテーブルは、直属の上司のIDだけでなく、組織図上で上にある全ての上司のIDを保持しています。
| company_code | founder |
|---|---|
| C1 | Monika |
| C2 | Samantha |
| lead_manager_code | company_code |
|---|---|
| LM1 | C1 |
| LM2 | C2 |
| senior_manager_code | lead_manager_code | company_code |
|---|---|---|
| SM1 | LM1 | C1 |
| SM2 | LM1 | C1 |
| SM3 | LM2 | C2 |
| manager_code | senior_manager_code | lead_manager_code | company_code |
|---|---|---|---|
| M1 | SM1 | LM1 | C1 |
| M2 | SM3 | LM2 | C2 |
| M3 | SM3 | LM2 | C2 |
| employee_code | manager_code | senior_manager_code | lead_manager_code | company_code |
|---|---|---|---|---|
| E1 | M1 | SM1 | LM1 | C1 |
| E2 | M1 | SM1 | LM1 | C1 |
| E3 | M2 | SM3 | LM2 | C2 |
| E4 | M3 | SM3 | LM2 | C2 |
各会社ごとに、各役職がそれぞれ何人勤務しているかを集計して出力してください。
出力の形式は以下のようにするよう要求されています。
- 会社ID 設立者の名前 Lead Managerの数 Senior Managerの数 Managerの数 Employeeの数
- 出力は会社IDの辞書順に並び替える
また、テーブルの中に重複レコードが存在しますので、集計時に取り除きましょう。
C1 Monika 1 2 1 2
C2 Samantha 1 1 2 2各テーブルが、組織図上で上にある全ての上司の情報を含んでいるため、表を結合する必要がありません。
集計は問題の見た目より簡単です。
重複レコードをDISTINCTで取り除くことを忘れずに。
1つのテーブルに含まれるレコード同士を比較する問題です。
X, Yの2つの数字の対応が保存されたFunctionsテーブルが1つ与えられます。
| X | Y |
|---|---|
| 10 | 20 |
| 20 | 10 |
| 15 | 30 |
| 15 | 20 |
| 30 | 15 |
Functionsテーブルの中から、XとYを入れ替えたら同じになるようなレコードのペアを見つけ出力してください。
例えば、上のテーブルでは、1行目と2行目、3行目と5行目の2組のペアがあります。
出力形式に対する要求として、
- ペア1組につき1行出力する。2つのうちX <= Yのレコードの方を出力する
- 出力は、Xが若い順に行を並び替える
(X, Y)= (10, 20)と、(X, Y)=(15, 30)を出力します。
10 20
15 30同じテーブルに含まれるレコード同士を比較するために、EXSISTS句を使用した相関サブクエリの形になっています。
同じレコード同士を比較してペアと判定しないように、予め連番を振っておく実装です。
Symmetric Pairsに引き続き、レコード間比較が必要になる問題です。時系列データを扱います。
タスクを管理する1つのprojectsテーブルが与えられます。projectsテーブルには、タスクのID、開始日、終了日が保存されています。
| Task_ID | Start_Date | End_Date |
|---|---|---|
| 1 | 2024-10-01 | 2024-10-02 |
| 2 | 2024-10-02 | 2024-10-04 |
| 3 | 2024-10-04 | 2024-10-05 |
| 4 | 2024-10-06 | 2024-10-08 |
| 5 | 2024-10-08 | 2024-10-09 |
projectsテーブルの中で、タスクの終了日(End_Date)とタスクの開始日(Start_Date)が一致する、連続した複数のタスクがあったとき、それらはともに同じプロジェクトの一部です。
例えば、上記のprojectsテーブルには2つのプロジェクトが存在し、スケジュールは以下のようになります。
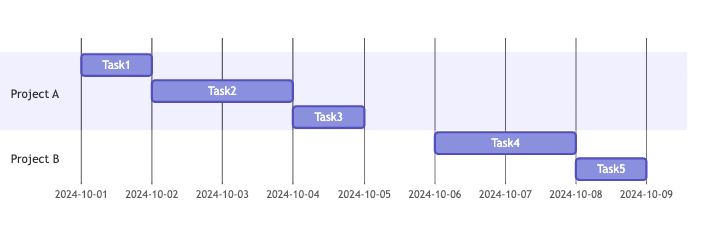
projectsテーブルに保存されたタスクのスケジュール
projectsテーブルのタスクを、プロジェクト毎にまとめ、各プロジェクトの開始日と終了日を出力してください。
出力に対する要求は以下の2つです。
- プロジェクトごとに1行出力する。出力は、プロジェクトの日数が短い方から順に並べる
- 同じ日数のプロジェクトが複数あったら、開始日が早い方から並べる
1つ目のプロジェクトは4日間、2つ目は3日間のスケジュールですから、2つ目を先に出力します。
2024-10-06 2024-10-09
2024-10-01 2024-10-05時系列データという意味でも、レコード間比較という意味でも、ウィンドウ関数を使用する解法が連想されますね。
通常のプログラミング言語なら簡単な問題ですが、SQLではどうしたらいいでしょうか。
入力となるテーブルはありません。
1000以下の素数を列挙し、アンパサンド”&”で結合して出力してください。
1000以下を列挙すると書ききれませんので、例えば10以下の素数を列挙する場合の出力を記載します。
2&3&5&7一旦0 ~ 9の数字をもつDigitsテーブルを作成し、Digitsテーブルの数字を使って、1000以下の数字を全て保持するSequenceテーブルを作成しました。
その後、Sequenceテーブルの中から素数を抽出しています。
SQLでは、使用するデータは全てテーブルに持たなければなりません。この問題はSQLに明らかに「向いていない」操作を要求していますが、なんとかできなくはないというところです。

